ONOS 强一致性算法raft的java实现版copycat代码分析之leader election
2015-05-01
首先引用并且概况来自SDNLAB的文章ONOS高可用性和可扩展性实现初探作为学习的入点,
概况文章要点
ONOS中一致性主要分为两种类型:一种是强一致性,其要求当一个实例更新网络状态时任何实例随后的读操作都返回最近更新的数值;另一种是最终一致性,它属于弱一致性,当系统保证如果没有新的状态更新时,最终所有的实例都能获得最后的更新保持最终状态一致,中间允许读取操作延后一段时间。强一致性 算法采用的是由zookeeper-->hazelcast-->raft转变的过程,而最终一致性算法采用的是gossip
ONOS系统架构之高可用实现方案的演进 解释了由zookeeper-->hazelcast-->raft转变的原因:
不用zookeeper的原因:相对于ONOS来说,ZooKeeper是它的一个依赖子系统,因此在部署ONOS之外还要单独部署ZooKeeper服务,由于ZooKeeper中所有的数据都以ZNode表示,这些ZNode存储在ZooKeeper的Server上,Client要读的数据需要跨JVM访问Server。这样ONOS Instance就变成了zClient,那么当ONOS不同实例间需要同步数据时,需要通过TCP的方式从zServer上请求数据,这就导致了ONOS的性能会急剧下降,另外,ZooKeeper的zNode对数据大小有限制(zNode数据大小不能超过1M)。所以说ZooKeeper以服务的模式提供分布式一致性,对于ONOS有太多限制。
不用Hazelcast的原因:Hazelcast有个致命的问题,它还很不成熟,在版本升级中可能会不兼容。比如在ONOS1.1.0中依然有很多Hazelcast相关的Bug,这就意味着ONOS依赖于一个不成熟的库,风险会很大。另外一方面也取决于Hazelcast是否会因为支持ONOS而进行升级。万一版本升级,出现不兼容现象,那么已经部署的ONOS风险就更大了。把风险控制在自己能掌控的范围之中才是ONOS社区首先考虑的。在这种情况下,Raft就成了不二之选了。
ONOS中一致性算法的java版实现采用的是copycat,它包括 Leader election、 Log replication 、 Cluster membership changes 、 Log compaction 这四个特性。本文主要分析 Leader election 特性,要分析 copycat 中这个特性的具体代码实现,有两个前提:理解 raft 算法 和 掌握 java 8 新特性的部分语法,因此,文章结构主要分为三个部分:一是介绍 raft 算法;二是介绍 java 8 新特性的语法;三是具体分析 copycat 实现 Leader election 的流程代码。
raft 算法
Leader election算法参考论文 "In Search of an Understandable Consensus Algorithm"
其中文翻译版 《寻找一种易于理解的一致性算法》
简易描述版 《Raft一致性算法》
raft动画,有助于理解 《Raft动画》
raft官方网站,含有与raft相关的详细信息 《Raft官网》
相信 raft 理解起来应该不难,因为 raft 算法的动机就是寻找一种更加易于理解的 Paxos 算法,关于利用随机性来实现 Leader Election 算法,除了容易理解的好处之外,其中论文中的一句话“尽管在大多数情况下我们都试图去消除不确定性,但是也有一些情况下不确定性可以提升可理解性。尤其是,随机化方法增加了不确定性,但是他们有利于减少状态空间数量,通过处理所有可能选择时使用相似的方法。”,我认为通过随机化来减少状态空间数量是一个很大的好处。在通信协议中,CSMA/CD也是采用随机回退的机制来解决信道中通信的碰撞。
介绍java 8 新特性
学习java 8 新特性,主要推荐一本书Java SE 8 for the Really Impatient,主要学习:
Chapter 1 Lambda Expressions
Chapter 2 The Stream API
Chapter 3 Programming with Lambdas
Chapter 6 Concurrency Enhancements
这本书的练习题答案参考:Solutions-for-exercises-from-Java-SE-8-for-the-Really-Impatient。
关于java 8 这些新(黑)特(科)性(技)的加入,变化较大,同时带来的争议也较大,例如:在接口中增加默认方法和静态方法,它的主要一个动机是扩展原来的API,因此需要在之前版本的接口中增加方法,但是按照java的规则,其所有实现类必须要实现该方法,这样太麻烦,于是想出了默认方法(在接口中直接实现该方法),该接口的实现类就不用再实现该方法了,这明显改变了java接口的规则。
copycat 中 Leader election 的实现
在开始分析 copycat 中 Leader election 实现代码之前,为了确保大家看的代码都是一样的,需要将代码切换到 commit hash 为 d597c723ffe9dbbee2aa22f4bd68d8174410e054 的版本。
git reset --hard d597c723ffe9dbbee2aa22f4bd68d8174410e054
建议阅读copycat仓库代码下面的描述,有助于理解 Resource, Log, Cluster 等名词含义。
copycat 代码中提供了一个关于 Leader election 的例子 (LeaderElectingVerticle 类的 start 方法),根据这个例子,梳理 Leader election 的具体流程。
前期准备
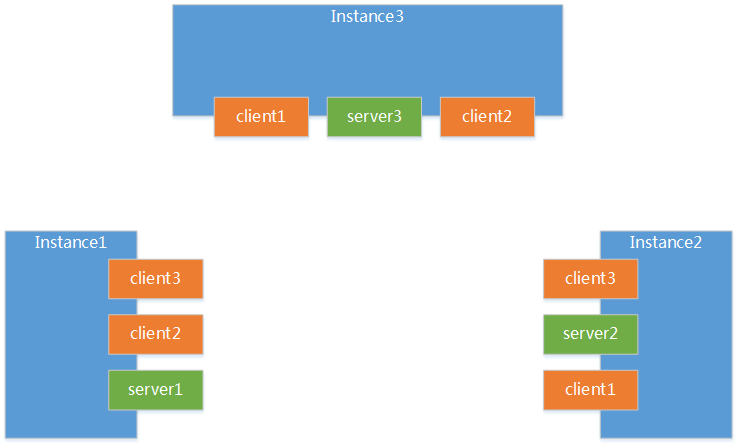
首先调用 LeaderElection 接口的静态方法create(黑科技), LeaderElection.create("election", cluster, config) ,代码里根据前期准备的 ClusterConfig 来实例化 ClusterCoordinator ,ClusterCoordinator 负责 Cluster 中各个 members 间的消息通信调度的核心。实例化 ClusterCoordinator ,本质上就是去定义 server 和 client ; 如下图, localMember(server) 和 remoteMembers(clients)
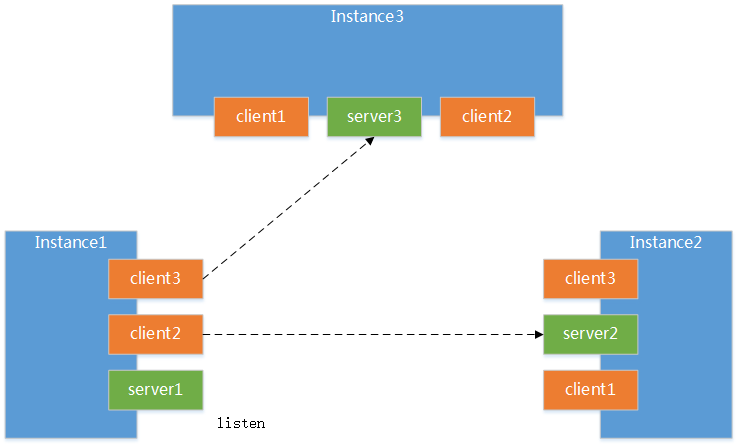
初始化完之后,开始添加 addStartupTask(() -> coordinator.open().thenApply(v -> null)) 其中,coordinator.open() 包括两个方面: cluster.open() 和 context.open() , cluster.open() 表示集群中各个节点与其他节点建立连接的过程,如下表示实例1的 open 过程,对于 localMember(server) 来说,它表示启动监听;对于 remoteMembers(clients) 来说,它表示建立与 server 间的连接。然后利用 gossip 协议来向集群中其他节点发送自己集群成员的信息,这样是为了同步集群中的成员信息。
选举实现
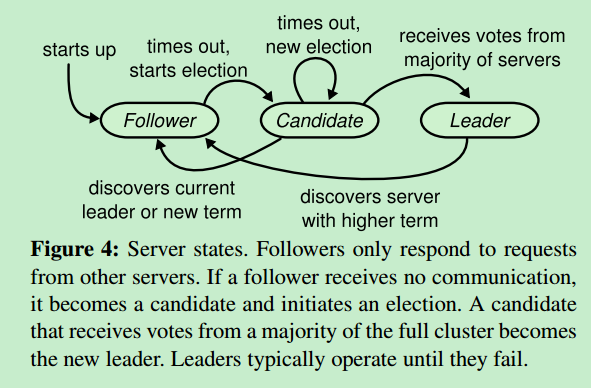
context.open() 显然 context 表示 RaftContext ,这里才是真正地选举开始,首先截取raft论文中的对状态转换描述的一张图如下
代码类图如下:
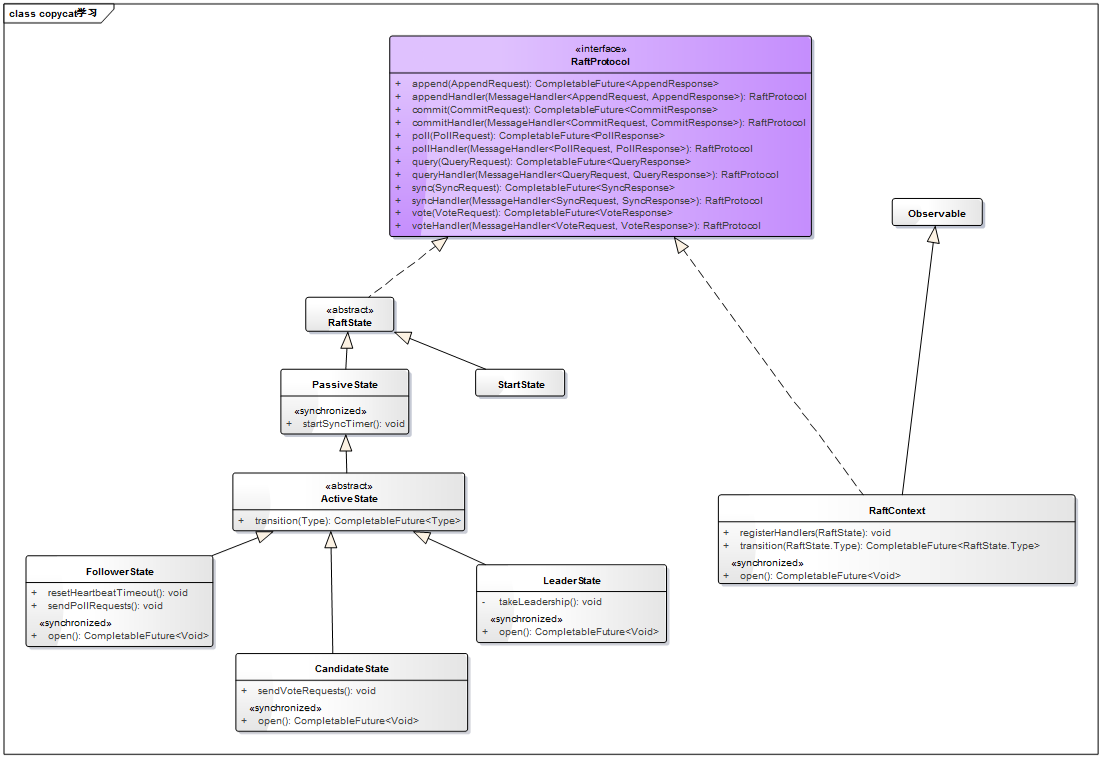 其中, RaftProtocol 接口定义了 raft 协议所需要的方法; RaftState 包含 Raft 的各个状态, Passive, Active(Follower, Candidate, Leader) 其中, ActiveState 继承 PassiveState 表明 ActiveState 包含 PassiveState 的所有操作; RaftContext 则记录节点当前 Raft 所需要的上下文信息,因此,这个类里面包含很多属性,另外,它还继承了 Observable 接口来完成观察者模式,当上下文中某些属性变化之后通知给实现了 Observer 接口的类 AbstractCluster。
其中, RaftProtocol 接口定义了 raft 协议所需要的方法; RaftState 包含 Raft 的各个状态, Passive, Active(Follower, Candidate, Leader) 其中, ActiveState 继承 PassiveState 表明 ActiveState 包含 PassiveState 的所有操作; RaftContext 则记录节点当前 Raft 所需要的上下文信息,因此,这个类里面包含很多属性,另外,它还继承了 Observable 接口来完成观察者模式,当上下文中某些属性变化之后通知给实现了 Observer 接口的类 AbstractCluster。
代码的入口从 RaftContext 的 open 函数开始的,如果配置中集群成员信息包含 localMember ,首先它将 RaftState 设置为 Follower ,否则, 将其设置为 Passive , 所有的状态转换都是调用的 RaftContext 的 transition 函数,它主要完成以下几件事:
- 根据 RaftContext 实例化需要转换的 state
- 为该 state 注册 handlers ,用于处理各个 topic(sync, append, poll, vote, query, commit, transition) 的消息
- 调用该 state 的 open 函数
本文主要讨论选举,从 Follower 为 open 方法开始,其状态机如下,
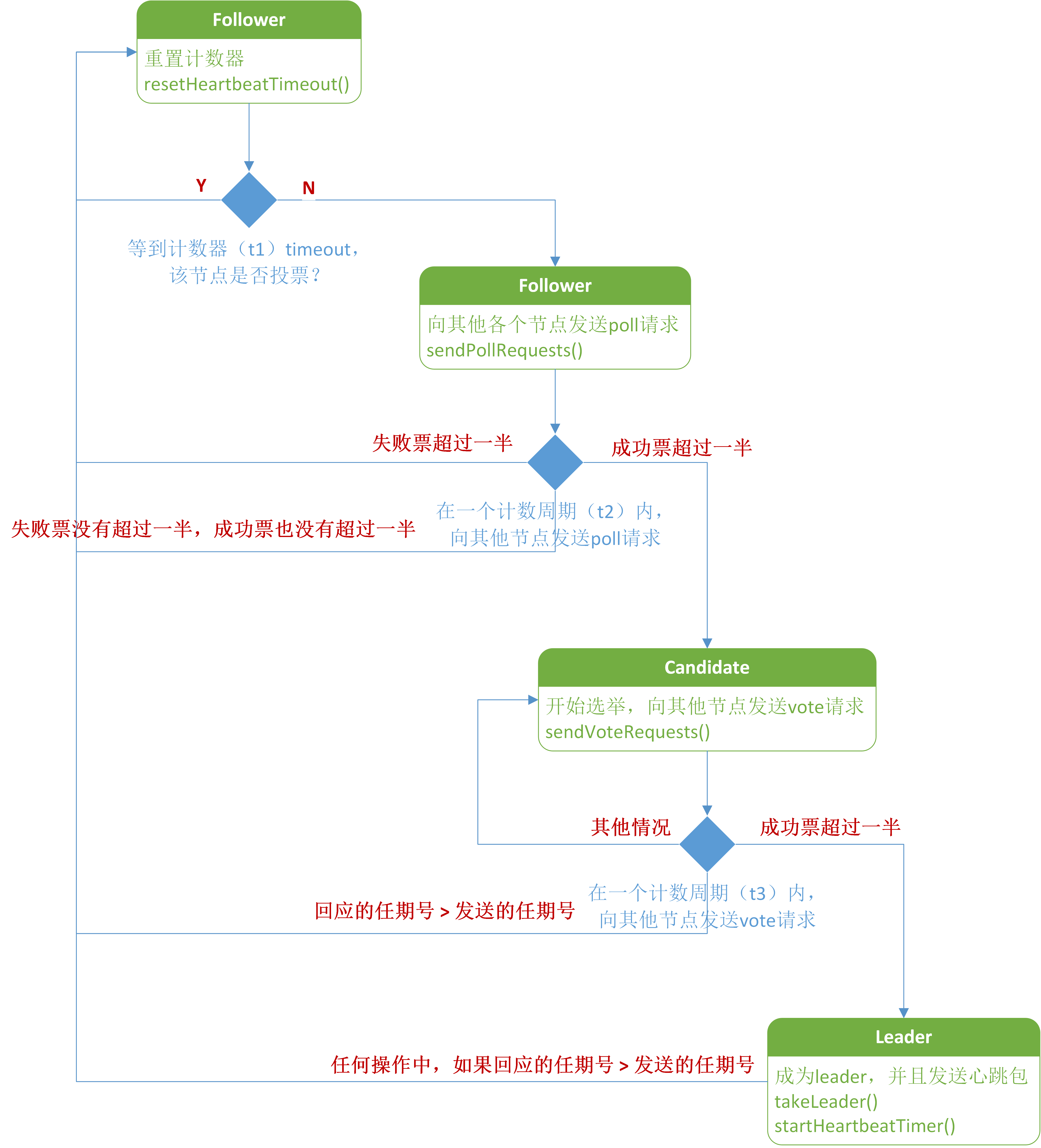
关于状态机有下面几点需要说明的:
- 相比论文中的状态转换,代码中多了 Follower:sendPollRequest 这个状态,它表示轮询集群中的其他节点,来决定是否应该进入 Candidate 状态,当其他节点收到 pollrequest 之后, Leader 直接回复 false (集群中已经有leader了,你不用参与选举了),其他 state 的节点根据其 pollrequest 中的 index, term 和自己的 lastIndex 和 term 比较(你的任期号比我小,那你还是先更新你的任期号再说吧。)
- 各个计数器的计时周期也是不一样的,主要分为两类:一类是图中的 t1, t3, t1 和 t3 是随机的,主要是为了更加高效地避免冲突;第二类是 t2 和 Leader 的 HeartbeatTimer ,它们是固定的,因为这种环境下,不需要避免冲突。