python编包工具setuptools
2016-09-06
本文以 AsyncMapTest 类中的testAsyncMapPutGet函数为引导,来完完整整的梳理一遍state-log replication的流程,来归纳整个copycat代码的结构。
研究setuptools中为何能够将setup.cfg的entrypoints中console_scripts的函数转化为命令, 他跟files中的scripts有何区别? 如果有多个python包使用了同一个命令,怎么解决冲突?。
zsh oh my zsh Why Zsh is Cooler than Your Shell
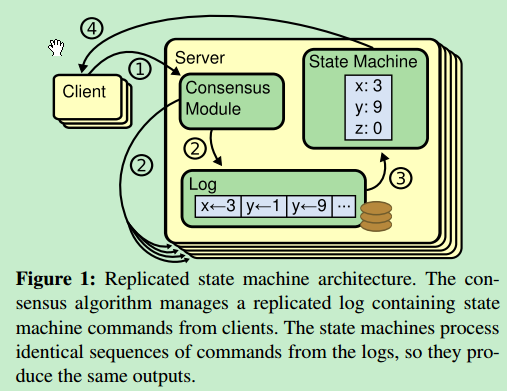
引用raft论文中一段话来描述日志复制的大体流程:
一旦一个领导人被选举出来,他就开始为客户端提供服务。客户端的每一个请求都包含一条被复制状态机执行的指令。领导人把这条指令作为一条新的日志条目附加到日志中去,然后并行的发起附加条目 RPCs 给其他的服务器,让他们复制这条日志条目。当这条日志条目被安全的复制,领导人会应用这条日志条目到它的状态机中然后把执行的结果返回给客户端。
日志复制主要讨论的是无论在哪种情况下, Leader 如何安全的将日志复制给集群中的其他节点。本文主要将 copycat 和 raft 论文的日志复制部分进行一一对照进行学习,目的有两点:
- 加深对 raft 算法的理解
- 学习代码技巧,设计模式,熟悉代码,以便对 ONOS 代码有更好地理解
关于日志复制,论文中讨论的情况有:
- Leader Crash
- Follower or Candidate Crash
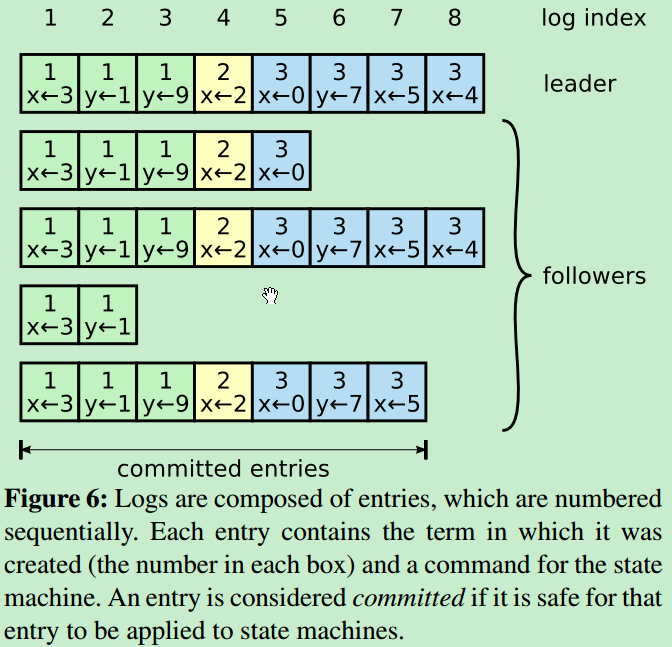
因为要完完全全保证上述两种情况,论文中还提出了一些 safety (限制),所以在讨论上述两种情况前,先对 safety 进行介绍,然后再分别讨论这两种情况。(另外前提还有论文中出现的一些术语,例如 term, log index 等),引用raft论文中的图来说明log组成:
Safety
为了保证整个过程的正确性,Raft算法保证以下属性时刻为真(这部分内容引用Raft一致性算法博客):
- Election Safety
在任意指定Term内,最多选举出一个Leader - Leader Append-Only
Leader从不“重写”或者“删除”本地Log,仅仅“追加”本地Log - Log Matching
如果两个节点上的日志项拥有相同的Index和Term,那么这两个节点[0, Index]范围内的Log完全一致 - Leader Completeness
如果某个日志项在某个Term被commit,那么后续任意Term的Leader均拥有该日志项 - State Machine Safety
一旦某个server将某个日志项应用于本地状态机,以后所有server对于该偏移都将应用相同日志项
直观解释:
为了便于大家理解Raft算法的正确性,这里对于上述性质进行一些非严格证明。
- Election Safety:反证法,假设某个Term同时选举产生两个LeaderA和LeaderB,根据选举过程定义,A和B必须同时获得超过半数节点的投票,至少存在节点N同时给予A和B投票,矛盾
- Leader Append-Only: Raft算法中Leader权威至高无上,当Follower和Leader产生分歧的时候,永远是Leader去覆盖修正Follower
- Log Matching:分两步走,首先证明具有相同Index和Term的日志项相同,然后证明所有之前的日志项均相同。第一步比较显然,由Election Safety直接可得。第二步的证明借助归纳法,初始状态,所有节点均空,显然满足,后续每次AppendEntries RPC调用,Leader将包含上一个日志项的Index和Term,如果Follower校验发现不一致,则拒绝该AppendEntries请求,进入修复过程,因此每次AppendEntries调用成功,Leader可以确信Follower已经追上当前更新
- Leader Completeness:为了满足该性质,Raft还引入了一些额外限制,比如,Candidate的RequestVote RPC请求携带本地日志信息,若Follower发现自己“更完整”,则拒绝该Candidate。所谓“更完整”,是指本地Term更大或者Term一致但是Index更大。有了这个限制,我们就可以利用反证法证明该性质了。假设在TermX成功commit某日志项,考虑最小的TermY不包含该日志项且满足Y>X,那么必然存在某个节点N既从LeaderX处接受了该日志项,同时投票同意了LeaderY的选举,后续矛盾就不言而喻了
- StateMachine Safety:由于Leader Completeness性质存在,该性质不言而喻
Leader Crash
首先 Leader Crash 可能导致 Leader 和 Followers 的不一致, Followers 有如下几种情况:
- 可能会缺少一些日志条目(a-b)
- 可能会有一些未被提交的日志条目(c-d)
- 或者两种情况都存在(e-f)
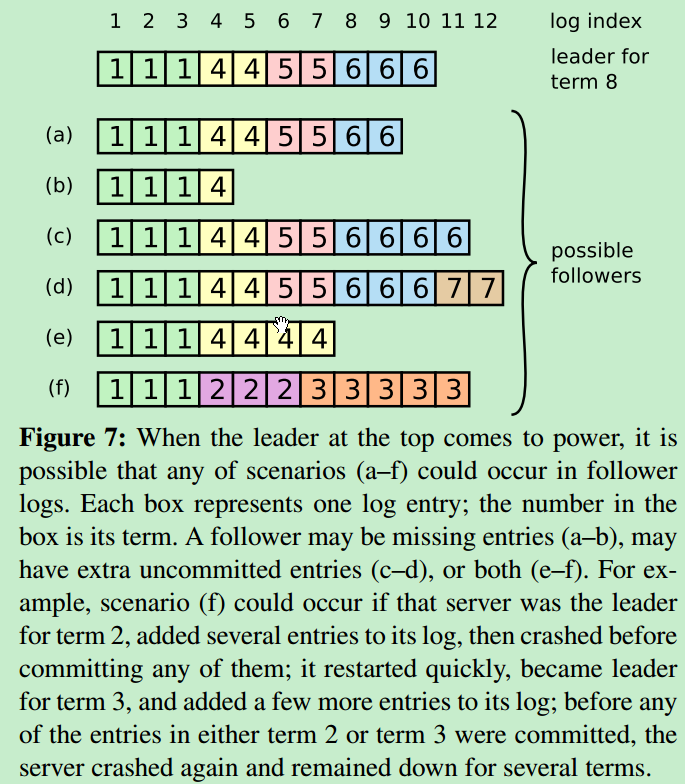
在 Raft 算法中,Leader 处理不一致是通过强制跟随者直接复制自己的日志来解决了。这意味着在 Followers 中的冲突的日志条目会被领导人的日志覆盖。这里应用 Leader Append-Only 特性。
思路:领导人必须找到最后两者达成一致的地方,然后删除从那个点之后的所有日志条目,发送自己的日志给跟随者。由 Log Matching特性可知,在那个点之前两者的日志完全一致,之后由 Leader 安全的将日志附加给他,这样达到两者完全一致。
具体做法:领导人针对每一个跟随者维护了一个 nextIndex,这表示下一个需要发送给跟随者的日志条目的索引地址。当一个领导人刚获得权力的时候,他初始化所有的 nextIndex 值为自己日志中的最后一条。如果一个跟随者的日志和领导人不一致,那么在下一次的附加日志 RPC 时的一致性检查就会失败。在被跟随者拒绝之后,领导人就会减小 nextIndex 值并进行重试。最终 nextIndex 会在某个位置使得领导人和跟随者的日志达成一致。当这种情况发生,附加日志 RPC 就会成功,这时就会把跟随者冲突的日志条目全部删除并且加上领导人的日志。一旦附加日志 RPC 成功,那么跟随者的日志就会和领导人保持一致,并且在接下来的任期里一直继续保持。
代码分析:接着 leader election 来讨论,转换到 Leader 状态之后,立马做的事情:( LeaderState 中的代码)
@Override
public synchronized CompletableFuture<Void> open() {
return super.open()
.thenRun(this::applyEntries)
.thenRun(replicator::commit)
.thenRun(this::takeLeadership)
.thenRun(this::startHeartbeatTimer);
}
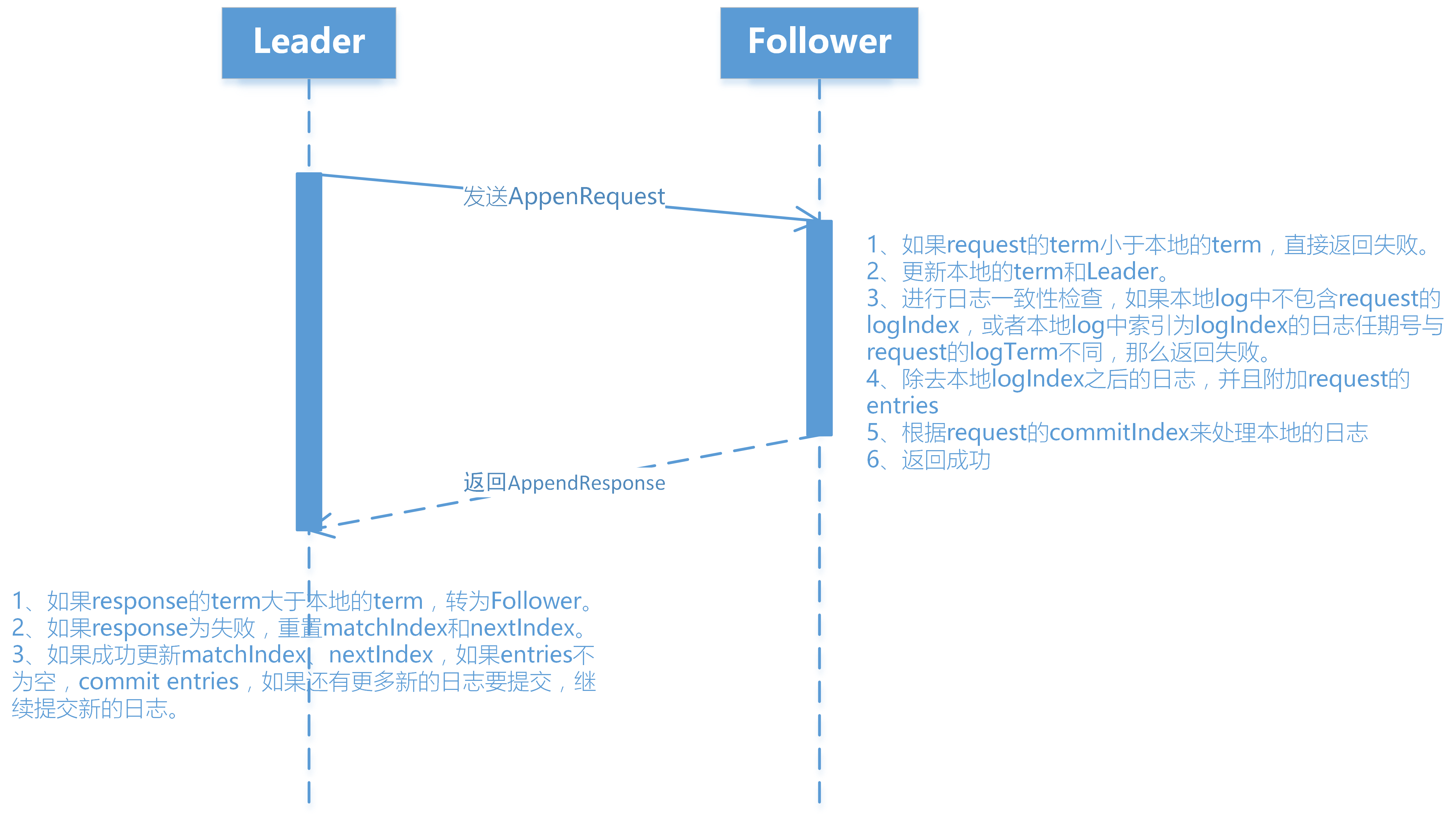
其中 replicator::commit为附加日志的入口,真正发送的函数是commit,该函数完成两个功能:发送附加日志请求AppendRequest给集群中Follower节点和处理来自集群Follower节点的附加日志AppendResponse。
- 发送附加日志请求
下图是Leader向每个Followers发送的附加日志请求,图中每个字段都对应它的含义。
 下图是附加日志的交互图
下图是附加日志的交互图
Follower or Candidate Crash
跟随者和候选人崩溃后的处理方式比领导人要简单的多,并且他们的处理方式是相同的。如果跟随者或者候选人崩溃了,那么后续发送给他们的 RPCs 都会失败。Raft 中处理这种失败就是简单的通过无限的重试;如果崩溃的机器重启了,那么这些 RPC 就会完整的成功。如果一个服务器在完成了一个 RPC,但是还没有响应的时候崩溃了,那么在他重新启动之后就会再次收到同样的请求。Raft 的 RPCs 都是幂等的,所以这样重试不会造成任何问题。例如一个跟随者如果收到附加日志请求但是他已经包含了这一日志,那么他就会直接忽略这个新的请求。